Arrays in PostgreSQL quick example¶
What is an array in database?¶
PostgreSQL allows columns of a table to be defined as variable-length multidimensional arrays. Arrays of any built-in or user-defined base type, enum type, or composite type can be created. Arrays are not supper efficient way of doing things, but they are sometimes handy.
Create some test data¶
Suppose we have table like this:
CREATE TABLE survey_test (
id SERIAL,
gender CHAR(1),
school CHAR(2), -- can be: LO, TH, ZW
q_9 VARCHAR(10) -- can be: [A-J]{0,10}
);
Where we store this data:
INSERT INTO survey_test( gender, school, q_9) VALUES
('F', 'LO', 'ABCDEFG'), ('F', 'LO', 'ABCDEFG'),
('F', 'LO', 'ABCFGH'), ('F', 'LO', 'ABCGJ'),
('F', 'LO', 'ABCDEFG'), ('F', 'LO', 'ABCD'),
('F', 'TH', 'AG'), ('F', 'TH', 'AD'),
('F', 'TH', 'AFG'), ('F', 'TH', 'ABCDEFG'),
('F', 'TH', 'ABFG'), ('F', 'ZW', 'ABJ'),
('F', 'ZW', 'ABCDEFGHIJ'),('F', 'ZW', 'IJ'),
('F', 'ZW', 'I'), ('F', 'ZW', 'EIJ'),
('M', 'LO', 'ABCDHIJ'), ('M', 'LO', 'CFHJ'),
('M', 'LO', 'CHJ'), ('M', 'LO', 'BG'),
('M', 'LO', 'EFH'), ('M', 'LO', 'BJ'),
('M', 'TH', 'BE'), ('M', 'TH', 'ABD'),
('M', 'TH', 'CDF'), ('M', 'TH', 'DI'),
('M', 'TH', 'B'), ('M', 'ZW', 'J'),
('M', 'ZW', 'C'), ('M', 'ZW', 'ABCDEFGH'),
('M', 'ZW', 'DFG'), ('M', 'ZW', 'AIJ');
Running sample query on data¶
So we want some simple statistics. Let’s display count of people of each gender which took our survey.
SELECT gender, COUNT(*) FROM survey_test GROUP BY gender;
gender | count
--------+-------
F | 16
M | 16
Get some advanced statistics about our data¶
We would like to know count of every answer which gave us each gender we can do it like this:
Attempt #1 - not optimized, bad looking SQL¶
SELECT s.gender, X.a, count(X.a)
FROM (
SELECT id,'A' as a FROM survey_test WHERE position('A' in q_9)>0
UNION ALL
SELECT id,'B' as a FROM survey_test WHERE position('B' in q_9)>0
UNION ALL
SELECT id,'C' as a FROM survey_test WHERE position('C' in q_9)>0
UNION ALL
SELECT id,'D' as a FROM survey_test WHERE position('D' in q_9)>0
UNION ALL
SELECT id,'E' as a FROM survey_test WHERE position('E' in q_9)>0
UNION ALL
SELECT id,'F' as a FROM survey_test WHERE position('F' in q_9)>0
UNION ALL
SELECT id,'G' as a FROM survey_test WHERE position('G' in q_9)>0
UNION ALL
SELECT id,'H' as a FROM survey_test WHERE position('H' in q_9)>0
UNION ALL
SELECT id,'I' as a FROM survey_test WHERE position('I' in q_9)>0
UNION ALL
SELECT id,'J' as a FROM survey_test WHERE position('J' in q_9)>0
) as X
INNER JOIN survey_test s ON (X.id = s.id)
GROUP BY s.gender, X.a
ORDER BY s.gender, X.a;
Informacja
INNER JOIN is used to easilly add new fields to result set.
It will work on almost all database systems available on the market (function position should be changed to other), but it will be performing rather terrible.
Query plan¶
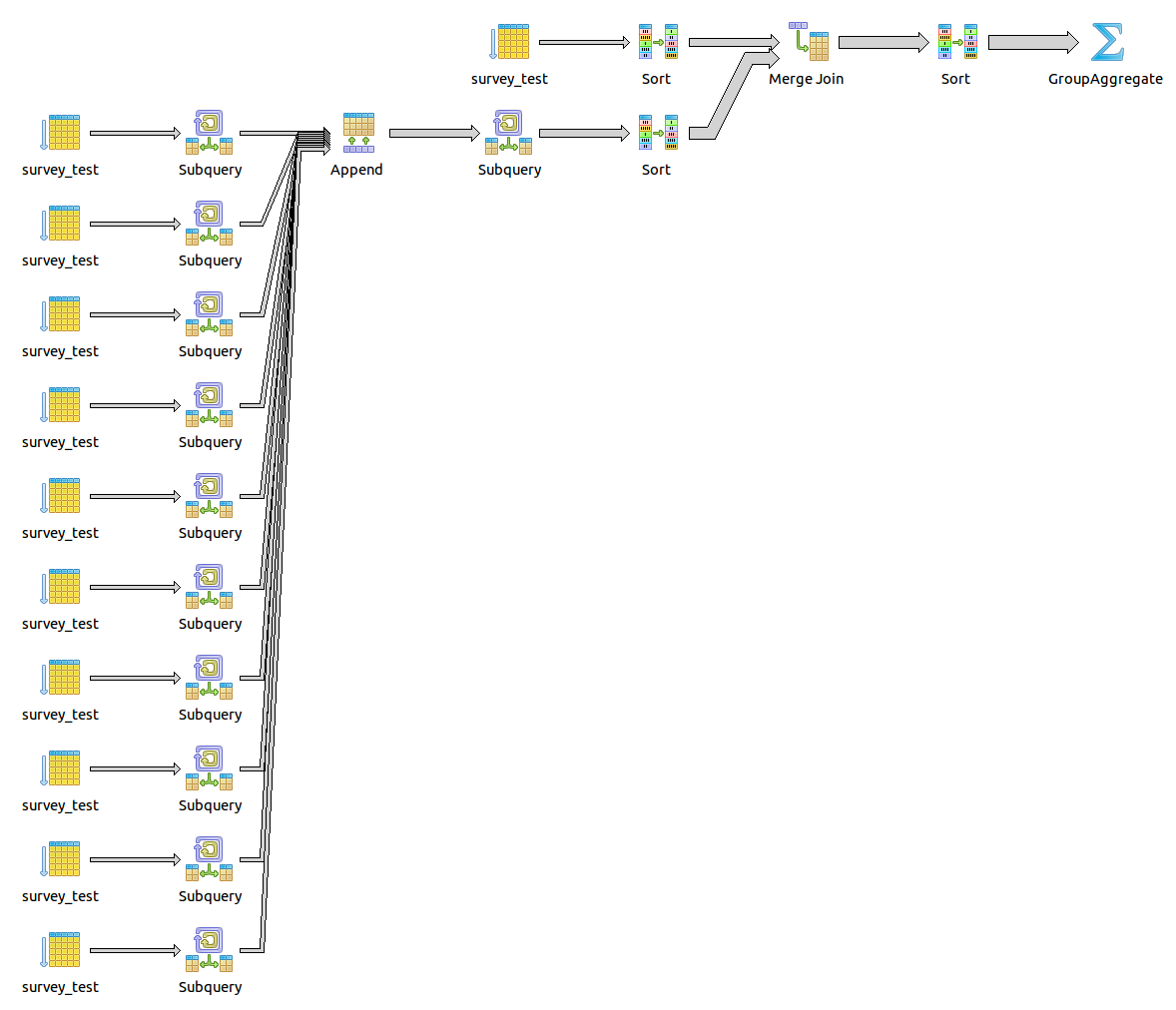
Results from not optimized query¶
As we can see plan is really extended, but query gives us nice results in 13.128 ms.
gender | a | count
--------+---+-------
F | A | 13
F | B | 10
F | C | 8
F | D | 7
F | E | 6
F | F | 8
F | G | 10
F | H | 2
F | I | 4
F | J | 5
M | A | 4
M | B | 7
M | C | 6
M | D | 6
M | E | 3
M | F | 5
M | G | 3
M | H | 5
M | I | 3
M | J | 6
(20 rows)
Right, so we want to optimize this a little bit, make it easy to maintain and so on …
Optimization, and arrays to the rescue!¶
Here it is the query which returns exact the same information but uses some advanced PostgreSQL operators:
SELECT
gender,
unnest( regexp_split_to_array(q_9, E'\\s*') ) AS a,
count(*)
FROM
survey_test
GROUP BY gender,a
ORDER BY gender,a;
Query plan of optimized query¶
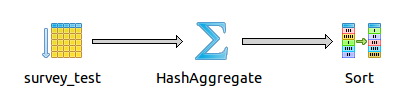
Results from optimized query¶
Results returned in 5.388 ms, and guess what they are exactly the same as from unoptimized version.
gender | a | count
--------+---+-------
F | A | 13
F | B | 10
F | C | 8
F | D | 7
F | E | 6
F | F | 8
F | G | 10
F | H | 2
F | I | 4
F | J | 5
M | A | 4
M | B | 7
M | C | 6
M | D | 6
M | E | 3
M | F | 5
M | G | 3
M | H | 5
M | I | 3
M | J | 6
(20 rows)
Conclusion¶
Arrays are handy feature in Postgre, but on large data sets they can be slow (heard that), arrays are stored in memory (got some free memory?). I rather don’t recommend use arrays in your everyday SQL code, but from time to time when generating some report on rather small data set it can be lifesaver if you don’t want to write application.
Additional references¶
I would like to know if you know other way to get exactly the same results without using arrays? Please post it in comments below.